Understanding Vectors
What is a vector?
vectors are objects which have both length (magnitude) and direction. You can consider it as a directed line segment.
Vectors are represented as a tuple (v1, v2, v3, …, vn) where each element represents a dimension/component (can say characteristic or property) of the vector.
When plotting these in vector space, vectors get their direction and magnitude based on the values in the tuple.
For better understanding, lets take some living things as objects. Describe the vectors based on their running speed and ability, size of the living thing, ability to fly.
Representing Animals as Vectors
| Animal | Running Speed (X) | Size (Y) | Flying Ability (Z) | Vector |
| Cheetah | 10 | 3 | -1 | (10, 3, -1) |
| Dog | 8 | 4 | -1 | (8, 4, -1) |
| Cat | 6 | 3 | -1 | (6, 3, -1) |
| Hen | 3 | 2 | 4 | (3, 2, 4) |
| Bee | -2 | 1 | 8 | (-2, 1, 8) |
| Butterfly | -3 | 1 | 7 | (-3, 1, 7) |
Lets plot these in a 3D vector space (we have taken 3 factors to describe the objects).
Image #1:
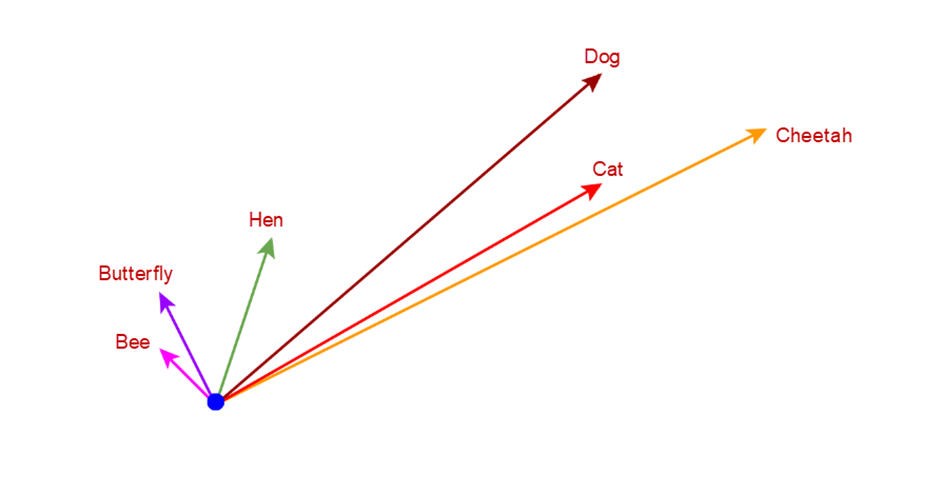
From the above image you can understand that the butterfly and bee are into similar directions, dog, cat, and cheetah are into similar directions. This happens due to the difference in the factors (represented as vector) that we took to plot these animals.
| Facts:Vector vs. Scalar: A scalar only describes “how much” (e.g., speed), while a vector describes “how much and which way” (e.g., velocity) |
How vectors can be used to find Word Embeddings?
Word embeddings are used to understand the word’s context and the relation between the words. As Vectors can represent similar objects in similar direction, we can use vectors to find the similarity of the words for word embeddings.
Now how do we define the vector based on word’s similarities?
Word embeddings are learned by training a neural network to predict the context of words.
We pass the neighbour words to the neural network and train it. While training, the words that often appear together or co-occur (neighbours) are trained with similar numerical values (weights). These weights are adjusted continuously (in back propagation) to reduce the prediction error. And so similar words get similar numerical representation which is called vector.
For example, bank, interest, loan, tax, money are used together and so the weights were adjusted to put these vectors in a similar direction. The magnitude may differ based on the duplication, occurrences, training patterns of the model etc.
The words recipe, ingredients, cook, boil, fry are not related to the words related to bank, interest etc. So, these words get similar direction and the direction of these 2 categories will highly differ from each other as there are very less possibilities of co-existing of these 2 categories in same document or paragraphs or pages.
Finally, each word gets multi-dimensional vector as a numerical and semantical representation.
Relation between vectors:
Now, Lets take 2 objects in vector space. How do you know the relation between these 2 objects?
Lets see the objects in Vector space.
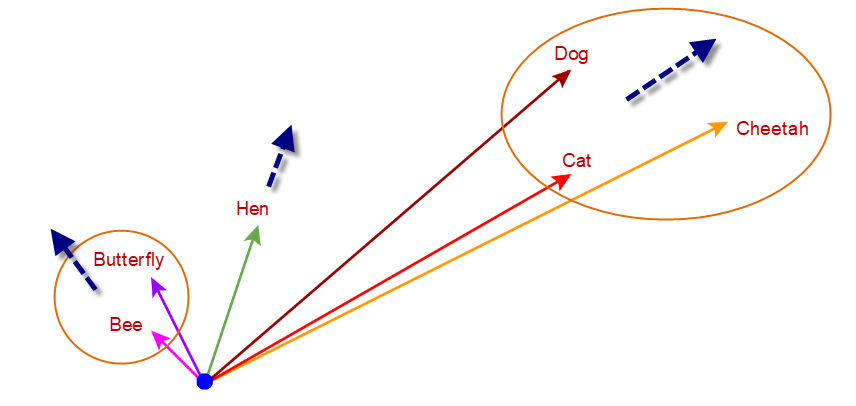
from the image #1, you can see that dog, cat and cheetah are in similar direction. Bee and Butterfly are in different direction.
You might think why can’t we use the magnitude but distance.
The lines are smaller for bee and butterfly. Imagine that you train the network with large documents about bee and butterfly. The magnitude might get stronger and becomes a larger magnitude. But still remains in the same position/direction.
In machine learning models, magnitude often represents:
- Confidence: How sure the model is about a word.
- Frequency: How often the word appeared in the training data.
- Importance: The weight the model assigns to that specific entry.
If “cat” appears 1,000 times and “kitten” appears 5 times, their magnitudes will be vastly different. Euclidean distance would suggest they are unrelated simply because one vector is much longer than the other.
Even in our example, if “bee” appeared 5000 times and “butterfly” appeared 5 times then the magnitude will highly differ but the angle remains same.
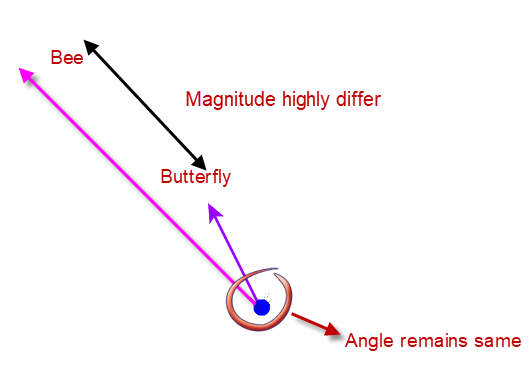
The way to measure the magnitude/length of the objects is Euclidean Distance. As the magnitude is affected highly by the confidence, frequency or importance or the way the model is trained.
The Solution: Cosine Similarity
To find true similarity, we want to ignore the length (magnitude) and focus only on the angle between the vectors, which remains same even though the usage of words differ in training the model.
The angle measurement is called Cosine Similarity.
The Math
We start with the Dot Product, which measures the interaction between components:
Lets take 2 vectors (objects) A & B.
A . B = ||A|| ||B|| cos(theta)
Since we want to “remove” the effect of magnitude, we divide the dot product by the product of the magnitudes:
cos(theta) = A . B / ||A|| ||B||
This leaves us with only the direction and this way of calculating the direction between 2 vectors is called Cosine Similarity.
Lets take some Practical examples for more understanding.
Case A: Perfect Similarity (Same Direction)
- Vector A: [1, 2, 3]
- Vector B: [2, 4, 6] (This is just Vector A, but twice as long)
- Result: cos(theta) = 1
- Interpretation: Even though B is further away in space, they have perfect similarity because they point in the exact same direction.
Case B: High Similarity (Close Directions)
- Vector A: [1, 2, 3]
- Vector B: [2, 5, 7]
- Result: cos(theta) is approx 0.99
- Interpretation: These are “almost similar.” The directions are nearly aligned.
Case C: No Similarity (Different Directions)
- Vector A: [10, 2, 30] (Strong in 1st and 3rd dimensions)
- Vector B: [2, 400, 6] (Strong in 2nd dimension)
- Result: $\cos(\theta) \approx 0.07$
- Interpretation: Close to 0. These vectors do not align at all; they are effectively unrelated in context. When we look at the numbers, the first and third parameters of the objects are very large for A. If you consider these as Size and Intelligence of an animal, then the vector B is very low in these 2 parameters. If you see the second parameter as “domestic” then Vector B’s second param is High and Vector A lacks in it. Vector A could be a dangerous large intelligent animal (Dinosaur in a funny note) and Vector B could be a dog.
Hope these examples help you to understand the vectors and its similarities.
Summary
Vectors are effective for representing words in numerical form because they have both magnitude and direction, which provides a meaningful representation in vector space.
Words used in similar contexts are clustered together in the same direction.
Cosine Similarity is the gold standard for comparing text because it captures the intent of the data without being distracted by how often a word appears.
Very Informative and clearly explained. Keep writing Asha 👏👏