5 Part series of most important Data Pre-Processing Techniques of Machine Learning:
- Part 5 – Dimensionality Reduction – Will be published soon
Data Source used in this article:
We will use the US Census data from Kaggle, from which we have to predict the income of the people.
import pandas as pd
census = pd.read_csv("adult.csv")
census.head() #By default returns first 5 rows of data
Before start processing, we need to know our data.
The info() function of pandas.
census.info()
Encode Categorical Values:
Machine learning algorithms cannot work on string data. It can only work on numerical data. So, the categorical data should be encoded to numerical data.
But in our data there can be any categorical values.
Example:
Ratings: Good, Bad
Education Level: Bachelors, Masters, Doctorate, Preschool, Higher Secondary
There are many ways to change the categorical values to numerical values. A few of them are,
- Ordinal Encoding
- One-Hot encoding
- Dummy Encoding
- Effect Encoding
- Target Encoding etc.
In this article, we will use One-Hot Encoding and Ordinal Encoding.
Categorical Data can be divided into 2 categories
- Nominal:
- These data do not mean any order. Example: Color of a product: White, Black, Red, Green, Yellow.
- Each category just represents a color and there is no information about the which color has high and which color is less valuable. So all the colors can be considered as equal importance.
- Ordinal:
- These data do mean a value for each category.
- Example:
- Ranking in review of a product: Very Good, Good, Moderate, Bad, Worst
- Cancer disease severity scale: Stage I, Stage II, Stage III, Stage IV
When converting a categorical data to numerical data, there should not be any loss of information.
When giving equal weightage to the stages will loose the meaning of the severity scale. But in case of colors, there should be no difference in weightage for any of the color.
To retain the information for the ordinal data, we can just convert the categories to numbers in the same order from 0 to any number. This is called Ordinal Encoding.
For Ordinal data, use Ordinal Encoding to retain the weightage of the categories.
For Nominal data, use One-Hot Encoding to avoid giving weightage to any of the categories and provide equal importance to all the categories.
Example:
- Stage I => 0
- Stage II => 1
- Stage III => 2
- Stage IV => 3
- Very Good => 0
- Good => 1
- Moderate => 2
- Bad => 3
- Worst => 4
When
Ordinal Encoding using sklearn.preprocessing.OrdinalEncoder:
How to a achieve this? We can manually replace the categories to a specific numeric values using pandas replace. But there is an efficient option than this.
In case if we want to encode the education column from census data in ordinal way (Just as an example to learn Ordinal Encoding.
Definitely, any education is not less here), we can use Ordinal encoding (As of now forget the education_num column.
In this data, as we have education_num, we do not need education column itself in the model as both the column represents same information).
from sklearn.preprocessing import OrdinalEncoder
census['education'].unique()
array(['Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'], dtype=object)
census['education']
0 Bachelors
1 Bachelors
2 HS-grad
3 11th
4 Bachelors
...
4995 5th-6th
4996 HS-grad
4997 HS-grad
4998 HS-grad
4999 Some-college
Name: education, Length: 5000, dtype: object
categories = [['Preschool', '1st-4th', '5th-6th', '7th-8th', '9th', '10th', '11th', '12th', 'HS-grad', 'Some-college', 'Assoc-voc', 'Assoc-acdm', 'Bachelors', 'Masters', 'Prof-school', 'Doctorate']]
ord_encoder = OrdinalEncoder(categories=categories)
ord_encoder.fit_transform(census[['education']])
array([[12.],
[12.],
[ 8.],
...,
[ 8.],
[ 8.],
[ 9.]])
ord_encoder.categories_
[array(['Preschool', '1st-4th', '5th-6th', '7th-8th', '9th', '10th',
'11th', '12th', 'HS-grad', 'Some-college', 'Assoc-voc',
'Assoc-acdm', 'Bachelors', 'Masters', 'Prof-school', 'Doctorate'],
dtype=object)]
Thus, we have converted the education column to a numeric column.
One-Hot Encoding using sklearn.preprocessing.OneHotEncoder:
Consider the relationship column from census data.
relationship_data = pd.DataFrame(['Not-in-family', 'Husband', 'Wife', 'Own-child', 'Unmarried', 'Other-relative'], columns=['relationsip'])
relationship_data
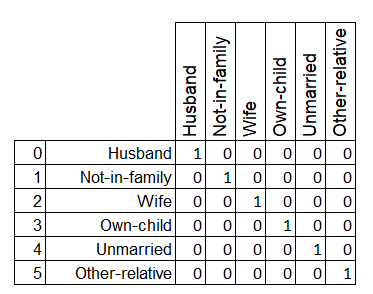
We cannot provide weightage to any of the status as the weightages does not mean anything to relationship data. One-Hot encoding does this.
One-Hot Encoding creates n number of dummy features for n number of categories. If a data point is of a Category then that corresponding dummy feature is set with 1 and all other dummy features will be set as 0.
Example:
This can be achieved using OneHotEncoding module of sklearn.preprocessing.
from sklearn.preprocessing import OneHotEncoder
onehot_encoder = OneHotEncoder(sparse=False)
relationship_encoded = onehot_encoder.fit_transform(relationship_data)
relationship_encoded
array([[0., 1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0., 0.]])
After encoding, the result can be merged with the original data and the corresponding original features should be dropped from the data.
Conclusion:
In this post we have seen the encoding types and how to do it.
This is a Part II of 5 part series of Data Pre-Processing tutorial.