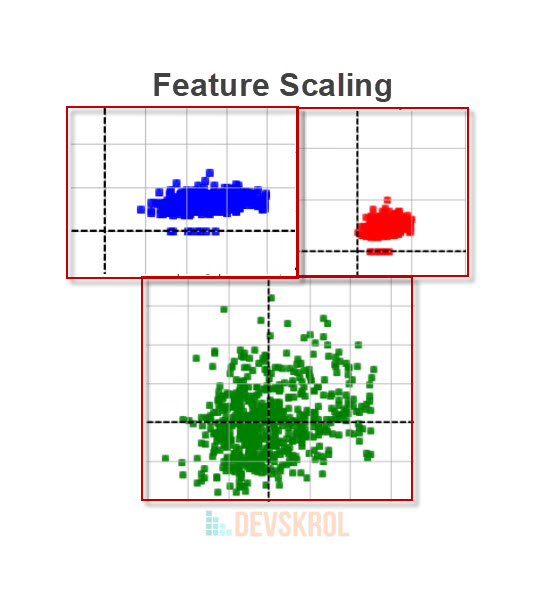
what, why and how to do Feature Scaling, Normalization Vs Standardization, common mistakes a beginner may do on Feature Scaling
what, why and how to do Feature Scaling, Normalization Vs Standardization, common mistakes a beginner may do on Feature Scaling
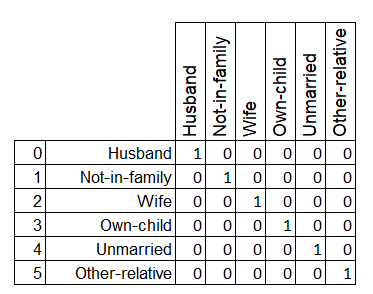
5 Part series of most important Data Pre-Processing Techniques of Machine Learning: Encode Categorical Values, One-Hot Encoding, Ordinal Encoding, Categorical Data types explained with examples
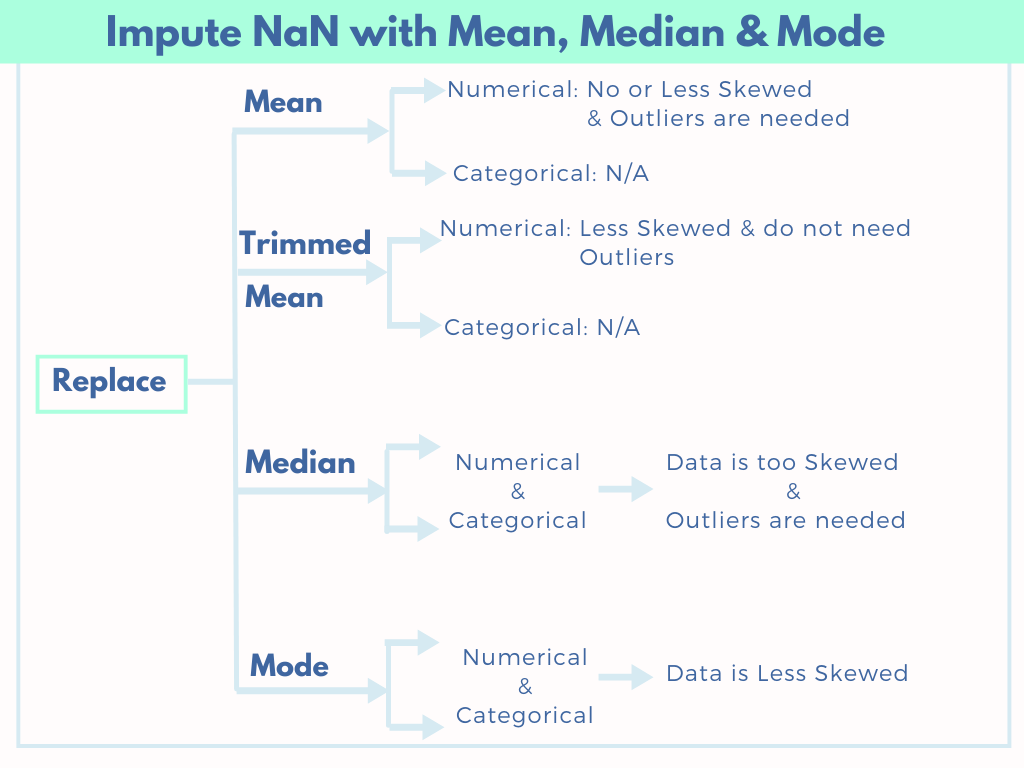
Major imputation techniques in Machine learning, US census data, Listwise Deletion, Impute NaN with mean, Trimmed Mean, median, mode, Drop columns if >60% of data is missing
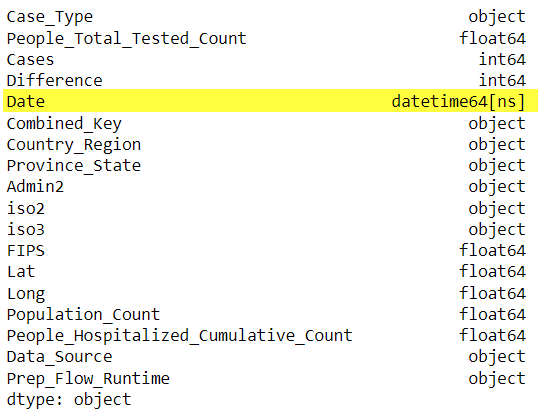
This is a 5 Part series of most important Data Pre-Processing Techniques of Machine Learning. Part 1 – Verify data types of the variables/features.

How to impute missing values using SimpleImputer and ColumnTransformer, Disadvantages of SimpleImputer, Advantage of ColumnTransformer
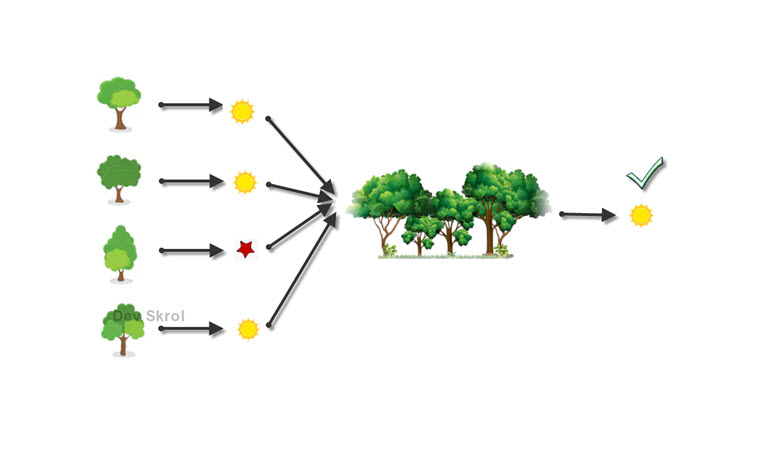
How Random Forest works? How to overcome Overfitting? What is Ensemble Learning? Why we need Random Forest? What is Bagging/Bootstrap Aggregation?
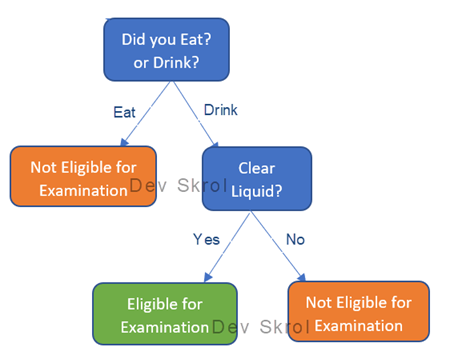
In this article we will learn about what is a Decision Tree? How it works? Why Decision Tree Overfitts & How can we resolve it?
In machine learning, training a model and testing it is definitely not an end. Should we run this source code of training, tuning everything again…
In this article we will be researching on the Titanic Dataset with Logistic Regression and Classification Metrics. Lets see how to do logistic regression with…

Logistic Regression – Cost Function, Error Metrics, Precision, Recall, Specificity, ROC Curve, F-Score, Observations from ROC Curve