Data Pre-Processing is a vital part in building a model. We will see most important Data Pre-Processing Techniques that can be used for Machine Learning.
This is a 5 Part series of most important Data Pre-Processing Techniques of Machine Learning:
- Part 5 – Dimensionality Reduction
In this article, we will see the first part of the series Part 1 – Verify data types of the variables/features.
Before going to the pre-processing techniques, we need to read data and import required libraries.
We will use the US Census data from Kaggle, from which we have to predict the income of the people.
import pandas as pd
census = pd.read_csv("adult.csv")
census.head() #By default returns first 5 rows of data
Before start processing, we need to know our data.
The info() function of pandas.
census.info()
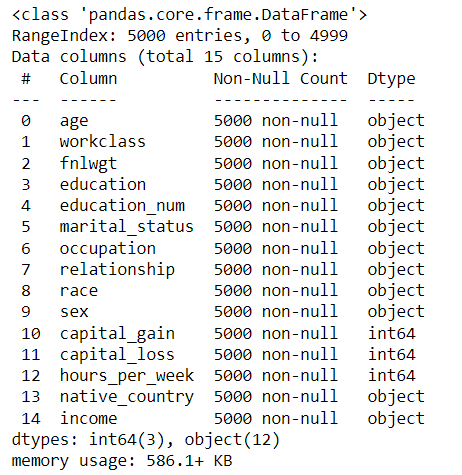
The above output provides datatypes, number of rows, null values etc.
Verify Data Types:
Basically, most of the data are collected from existing databases and the datatypes need not be in correct format. Sometimes the date values may not be in datetime format.
Lets take an example of data with date as one of the features.
COVID-19 Data Source:
- https://www.tableau.com/covid-19-coronavirus-data-resources
- https:/query.data.world/s/ydb5tncrsnsuh3tyzx5466o5hiacem
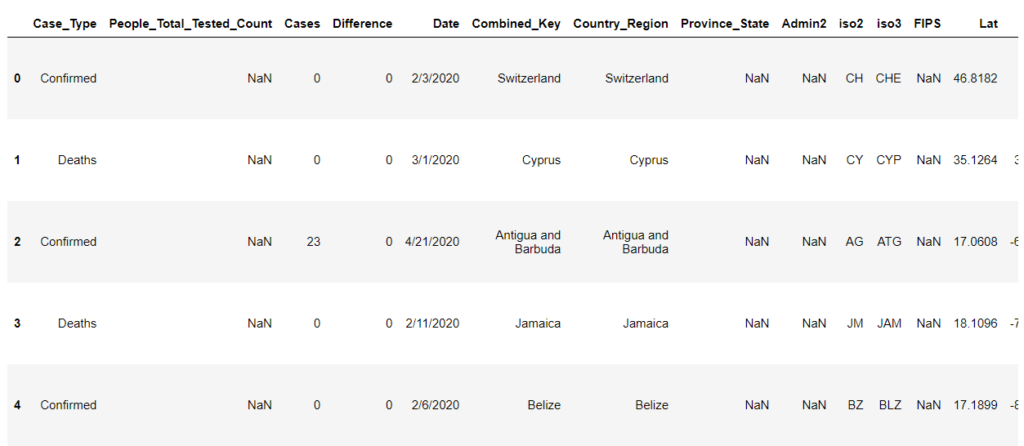
covid = pd.read_csv("COVID-19 Cases.csv")
covid.head()
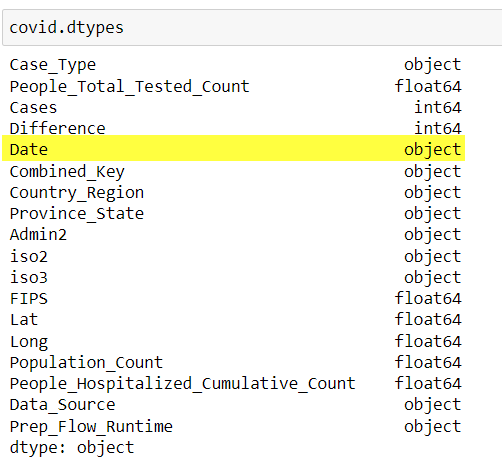
The dtypes attribute gives the datatype of all the columns.
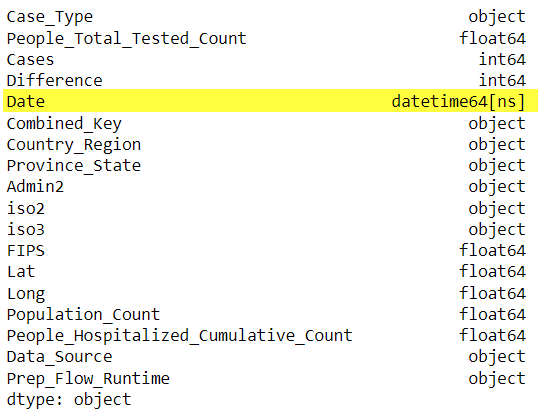
In some data that relies on date values, the data types need to be in datetime format. Example: Group data based on date, timeseries analysis etc.
To convert object/string values to datetime(64), pandas.DataFrame.astype() function can be used.
covid['Date'] = covid['Date'].astype('datetime64')
covid.dtypes
Similarly, we can convert objects to float, int etc.
Conclusion:
In this post we have learn how to correct data types.
This is a Part I of 5 part series of Data Pre-Processing tutorial.
Please find the remaining parts here.