In this article, we are going to learn how we get Random Forest from Decision Trees. How Random Forest works! How Ensemble learning helps to overcome Overfitting!
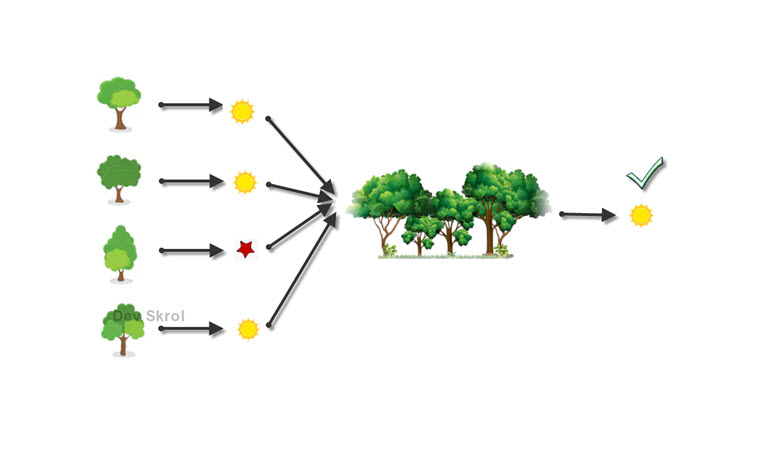
Random Forest is an ensemble of Decision Trees.
Ensemble Learning is a method of improving the Learning of a Machine Learning Model by combining several models to get better predictions.
Random Forest bags the data with replacement and creates a Decision Tree from each data. While predicting, it gets answers from all the trees and takes the majority results as the final prediction.
In this article, we will see this in detail with an example.
To know about decision tree, please check Decision Tree.
A solution to Overfitting with the help of Bootstrap Aggregating/Bagging:
The main problem we have in Decision Tree is, it is “Prone to Overfitting”.
Even though we can control it using parameters, it is a noticeable problem in DT.
Random Forest gives us a solution to overcome this problem.
Overfitting happens when our model learns too much with the training data, that means it learns from the noises also from the training data. But when the test data comes in play, the training received from noise makes the model to fail the prediction.
But we can say that the entire data is not a noise.
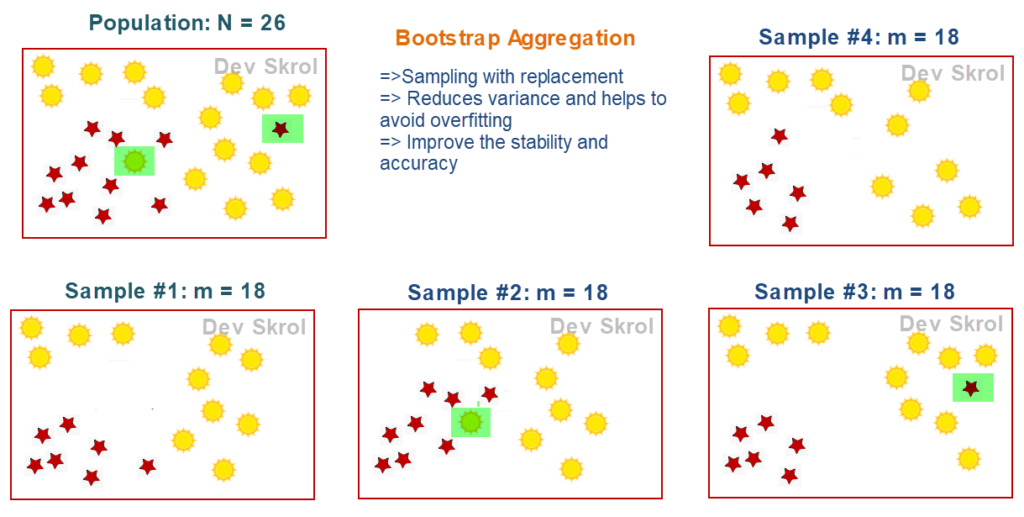
In the above picture, you can see that, from a dataset of size 26, 4 data sets have been drawn.
- All datasets are of same size.
- A data point existing in one dataset may or may not be existing in other datasets. That’s why we say it as “with replacement”. We did not place any condition when creating datasets, as a point given to one dataset will not be removed from the main dataset. We can say that we copy data points from main population randomly and creating m number of datasets.
- There is no restriction in number of datasets that sampled from population. However, each dataset is unique because there is at least 1 data point that differs from other datasets.
How Random Forest works?
N number of Weak learners make a Strong learner.
After bagging, we have n number of independent datasets with the same number of data.
Using the above 4 samples, a Decision Tree is modelled for each sample dataset. So each Decision Tree acts as a separate Model.

From the above picture, 4 Decision Trees gives results and the result which wins the majority voting is set as the final prediction value.
As all the datasets will not have the same data, the noisy data will not be existing in all the decision trees. There may be a few Decision Trees that has noisy data. However, due to the majority voting, those noisy data may be neglected.
Advantages of Random Forest:
- Overcomes Overfitting problem of Decision Trees.
- Gives High Accuracy as we are not going with one result of a Decision Tree and we are taking the best out of all results.
Conclusion:
In this article, we have learned that Random forest makes a strong learner from many weak learners.
Please find the Jupyter notebook for implementing Random Forest here.
Simple and nice explanation. Easy to understand ! Thanks for posting it Asha
Thank you Srikanth.