Part 2 of 3 — The Foundation Series on Prompt Optimization
A practical guide to DSPy — the framework that treats prompt engineering as a programming problem, not a craft problem.
The problem with hand-written prompts:
In Part 1, we built a great prompt using five parts: Role, Task, Context, Examples, and Format. We saw that better instructions produce better results — consistently.
But here is the problem that every AI product team eventually hits:
You have 8 modules in your pipeline. Each has its own prompt. Your evaluation shows module 3 is underperforming. You tweak its prompt. Module 3 improves. Module 5 gets worse. You fix module 5. Three weeks later, a new dataset exposes gaps in module 2. You start over.
You are spending more time engineering prompts than building product.
This is not a discipline problem. It is a tooling problem. And it has a solution.
The Solution – DSPy
DSPy (Declarative Self-improving Python) is an open-source framework from Stanford NLP, now stewarded by Databricks. Instead of writing prompts, you write Signatures — Python classes that define what goes in and what should come out of an LLM call. Then you run an Optimizer that automatically finds the best prompt to achieve that.
In DSPy, you define what your pipeline does — the modules, the inputs, the outputs, the flow.
The framework handles how to instruct the LLM to do each step. Those instructions — the prompts — are compiled automatically, not written manually, and saved in a JSON file that DSPy loads at runtime to assemble the prompt automatically — you never write or paste the prompt yourself.
You work at a higher level of abstraction, and a compiler handles the low-level details.
| Traditional prompting | DSPy |
|---|---|
| You write Role, Task, Examples, Format by hand | You define inputs, outputs, and a scoring metric |
| You iterate by editing strings and re-testing | You iterate by changing the metric and re-compiling |
| You own the prompt text | You own the structure and the metric |
| Prompts are brittle across models | Swap models, re-optimize — same structure works |
| More modules = more prompts to maintain | More modules = more to optimize together |
Before you use DSPy — quick checklist
Before you run a single line of DSPy code, make sure you can check all five boxes:
A defined task — you know exactly what goes in and what should come out. If you cannot fill in a Signature cleanly, the task is not ready yet.
30–50 labeled examples — real inputs paired with correct outputs, covering normal cases and edge cases. This is your training data.
A metric function — a Python function that scores a prediction against a label. If you cannot measure “good,” you cannot optimize for it.
Time and compute — You need to optimize your prompt. Optimization is a one-time cost but a real one. Budget 15–60 minutes of GPU time depending on your optimizer and dataset size.
A stable pipeline — you have decided how many LLM steps you need and how they connect. DSPy optimizes your pipeline, it does not design it.
If any box is unchecked, finish that first. DSPy rewards preparation. The more solid your inputs, the more powerful the output.
Who uses DSPy — with real examples
DSPy is in use by Research teams especially Stanford’s own STORM project, Shopify, Databricks, Dropbox, JetBlue, Moody’s, Replit ect.
Lets see how they use it:
=> Software Engineers & AI Developers
Example:
A team is building a legal document assistant. It needs to:
- Read a contract
- Identify the clause type
- Extract key dates and obligations
- Generate a plain-English summary
Each of those is a separate LLM step. Manually writing and maintaining 4 prompts that work reliably across hundreds of different contract formats is painful. With DSPy, they define each step as a Signature, label 40 example contracts, and let the optimizer find the best prompt for each step — together, as a pipeline.
Where in the cycle:
Mostly development — they run the optimizer when building the pipeline, when they add new clause types, or when they upgrade the underlying model. Production just loads the compiled result.
=> Enterprises & Startups
Example:
Shopify uses DSPy (with GEPA, covered in Article 3) for product metadata extraction — automatically reading product listings across millions of shops and extracting structured fields like category, material, size format, and target audience.
At Shopify’s scale, even a 2% improvement in extraction accuracy across millions of products is enormous business value. They can’t get that by hand-tuning prompts. DSPy lets them define the extraction task, measure accuracy against labeled examples, and run the optimizer to close the gap systematically.
Where in the cycle:
Both — development to optimize, production to run the compiled extractor at scale across every shop. Re-optimization happens when product categories expand or a new model becomes available.
=> Automated Prompt Optimization
Example:
A startup building a customer support chatbot finds that their intent classifier works well on simple messages (“cancel my order”) but fails on ambiguous ones (“I’ve changed my mind about everything”). They have 200 labeled examples.
Instead of manually rewriting the prompt until it handles edge cases, they define a metric (intent_accuracy), run MIPROv2, and let it search through instruction variants and few-shot combinations. The optimizer finds that injecting 3 specific edge-case examples and rewording the instruction from “classify the intent” to “identify the primary customer need, even when the message is indirect” pushes accuracy from 74% to 91%.
Where in the cycle:
Development — runs once (or again whenever they add new intents or gather more labeled data). Production just calls the compiled prompt.
=> Building RAG Pipelines
Example:
A healthcare company builds a RAG system where doctors can ask questions about drug interactions. The system searches a medical database and generates a response. The problem: the retrieval step pulls back relevant-sounding but slightly off documents, and the LLM sometimes fills the gap with hallucinated details.
With DSPy, they optimize the entire RAG pipeline — the search query formulation, how many documents to retrieve, and the generation instructions — together, using a metric that penalizes any answer not grounded in the retrieved documents. The optimizer finds that adding “only use information explicitly stated in the context” to the generation step and fetching 5 documents instead of 3 reduces hallucination rate by 40%.
Where in the cycle:
Development for optimization. The compiled pipeline runs in production, and they re-optimize quarterly as the medical database grows and new drug classes are added.
Who should not use DSPy (yet)
You have no labeled examples – DSPy’s optimizers — especially BootstrapFewShot and MIPROv2 — need examples to work with. Not thousands, but at least 20–30 cases where you know what the correct output should be. If you cannot answer “what does a good output look like for these specific inputs?” you cannot write a metric, and without a metric the optimizer has nothing to maximize. You would just be running a very expensive random search.
The exception is GEPA (Article 3), which can optimize with unlabeled data — but you still need a metric that can score outputs without ground truth labels.
Your task changes every week – DSPy optimization is a one-time cost that pays off over many inference calls. If your task definition, intents, or output format keeps shifting — you are adding new fields, removing old ones, changing what “correct” means — you will be re-running the optimizer constantly and spending more time compiling than deploying.
Your pipeline has only one LLM call – If your entire application is one prompt — “summarize this document,” “translate this sentence,” “classify this review as positive or negative” — the overhead of DSPy is probably not worth it. A single well-written prompt with a couple of hand-picked examples will work just fine. DSPy’s real power shows up when you have multiple chained steps where errors cascade, or when you have a complex output format that is hard to specify in words. For a single call, the return on investment is low.
Quick decision guide, Who can use it?
| Situation | Use DSPy? |
|---|---|
| Still exploring the idea | No — prototype first |
| No labeled data, no metric | No — label first |
| Task definition keeps changing | No — stabilize first |
| Need to ship today | No — optimize later |
| Single LLM call, simple task | Probably not |
| Multi-step pipeline, need reliability | Yes |
| Have data, have metric, need consistency | Yes |
| Switching models frequently | Yes |
Signatures — what you write instead of prompts
A Signature is a typed Python class that defines one LLM step. Here’s the one we’ll use throughout this article — intent classification for a customer care chatbot:
class ClassifyIntent(dspy.Signature):
"""Classify the customer support message into a single known intent."""
# ↑ Docstring — this becomes the Task instruction in the prompt
user_message: str = dspy.InputField(
desc="Raw message from the customer"
)
intent: str = dspy.OutputField(
desc="Exactly one of: track_order, cancel_order, refund_request, escalate, general_query"
)
confidence: float = dspy.OutputField(
desc="Confidence score between 0.0 and 1.0"
)That’s it. No “You are a helpful agent.” No format instructions. No manually chosen few-shot examples. Just structure.
Each line and word in this signature matters, including the DocString “Classify the customer support message into a single known intent”. Lets see which part contributes what in the prompt.
What is given as “desc” is optional in this definition but it is essential for the best prompt. So it is always recommended to provide “desc”. It will be used as a hint to LLM to understand the constraints. Here for example LLM will understand that the intent should be one of “track_order, cancel_order, refund_request, escalate, general_query”.
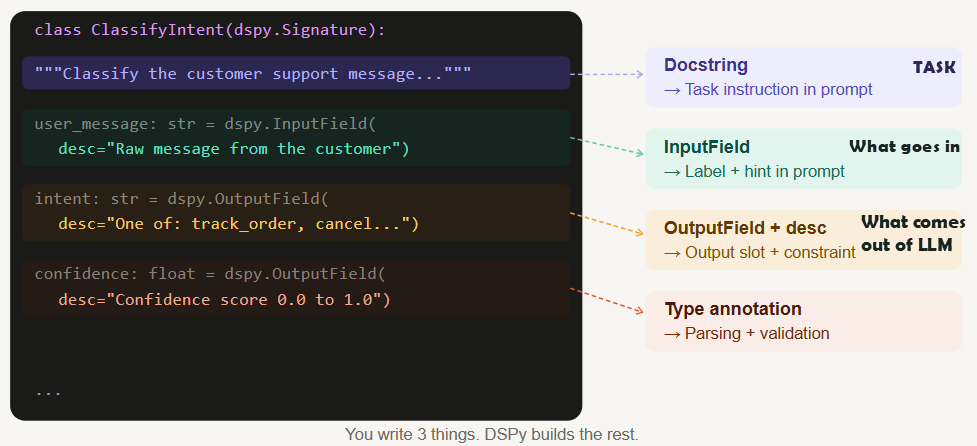
Now the prompt has the context. The main part is “Examples” & “Role” is still not yet composed by DSPy.
We have the sample data of user prompts and what to extract from the message and how the LLM should work for that
Chaining signatures into an agent
For our customer care chatbot, we need three LLM steps chained together. In DSPy, a Module does this:

class CustomerCareAgent(dspy.Module):
def __init__(self):
# dspy.Predict → direct answer, one LLM call
# dspy.ChainOfThought → adds reasoning step before answering
self.classify = dspy.Predict(ClassifyIntent)
self.extract = dspy.Predict(ExtractEntities)
self.respond = dspy.ChainOfThought(GenerateResponse)
def forward(self, user_message: str, policy_context: str = ""):
intent_result = self.classify(user_message=user_message)
entity_result = self.extract(user_message=user_message)
entities_json = json.dumps({...})
final = self.respond(
user_message=user_message,
intent=intent_result.intent,
entities=entities_json,
policy_context=policy_context,
)
return dspy.Prediction(
intent=intent_result.intent,
response=final.response,
)The key insight: when you run the optimizer, it doesn’t optimize each module in isolation. It optimizes the whole pipeline together — because a great intent classification that leads to a bad response is still a bad system.
How to generate Examples & Instructions
To find the best examples for your prompt, you need an optimizer to evaluate which is best and you need to define what is best.
Optimizer – An algorithm runs your LLM against the training dataset, scores the outputs, and searches for the best combination to find the best examples AND (in MIPROv2) the best instruction text
Metric – You define what is best, a calculation to find the score from the result of the training
Training data → gives the optimizer raw material to search through
+
Metric → tells the optimizer what score to maximize
+
Optimizer → runs the search, uses LLM to test candidates
↓
Best examples (+ best instruction) injected into your prompt automatically
Optimizers — the three families
An optimizer takes your module, trainset, and metric, and searches for the prompt that maximizes the score. DSPy has three main families:
BootstrapFewShot
Fast starter
What it optimizes
Few-shot examples only. Does not rewrite instruction text.
What you need
Labeled examples + metric
Use when
You want fast results with clean labeled data
Cost
Low — few LLM calls
MIPROv2
Best quality
What it optimizes
Instructions + examples jointly using Bayesian search.
What you need
Labeled examples + metric + teacher model
Use when
Quality is critical and you can afford more LLM calls
Cost
High — best results
GEPA
No labels needed
What it optimizes
Instructions via LLM self-reflection and evolution.
What you need
Metric only — no labeled examples required
Use when
Data is hard to label but you can write a metric
Cost
Medium — ICLR 2026
We will take MIPROv2 for our example which is widely used.
Lets see how to train and Optimize the prompt:
teacher = dspy.LM("ollama/qwen2.5:32b", api_base="http://localhost:11434")
student = dspy.LM("ollama/qwen2.5:14b", api_base="http://localhost:11434")
optimizer = MIPROv2(metric=intent_accuracy, auto="medium")
optimized = optimizer.compile(
student=CustomerCareAgent(),
trainset=trainset,
teacher_settings=dict(lm=teacher), # teacher proposes instructions
)Metric:
def intent_accuracy(example, prediction, trace=None) -> bool:
return (
example.intent.strip().lower()
== prediction.intent.strip().lower()
)MIPROv2 treats your prompt as having two variables it can optimize: the instruction text and the few-shot examples. Then it uses Bayesian optimization to search for the best combination of both.
Finally it produces a json, lets say miprov2_agent.json.
This JSON file contains 3 things:
- The optimized instruction text
- The best few-shot examples the optimizer selected
- The structure metadata DSPy needs to reassemble everything at runtime (in production)
Sample JSON file:
{
"classify": {
"lm": null,
"traces": [],
"train": [],
"demos": [
{
"augmented": true,
"user_message": "I've been waiting 3 weeks, this is completely unacceptable.",
"intent": "escalate",
"confidence": 0.97
},
{
"augmented": true,
"user_message": "Where is my package? Order #99102.",
"intent": "track_order",
"confidence": 0.95
},
{
"augmented": true,
"user_message": "I want my money back for order #55210.",
"intent": "refund_request",
"confidence": 0.93
}
],
"signature_instructions": "Identify the primary customer need, even when the message is indirect or emotional.",
"signature_prefix": "Intent:"
},
"extract": {
"demos": [
{
"user_message": "My order #45231 hasn't arrived.",
"order_id": "#45231",
"customer_email": "",
"issue_summary": "Customer's order has not arrived."
}
],
"signature_instructions": "Extract all structured data mentioned by the customer, returning empty string if not present."
},
"respond": {
"demos": [
{
"user_message": "I want a refund for my broken item.",
"intent": "refund_request",
"entities": "{\"order_id\": \"\", \"email\": \"\", \"issue\": \"Item arrived broken\"}",
"policy_context": "Refunds processed within 5-7 business days.",
"response": "I'm sorry to hear your item arrived damaged. We'll process a full refund within 5-7 business days to your original payment method. Could you share your order number so we can get this started?"
}
],
"signature_instructions": "Generate a polite, empathetic response that directly addresses the customer's issue using the policy context provided."
}
}This is the compiled output you need in production.
What goes to Production
The training set, the training code we used to run MIPROv2 (and the teacher model, if you have used different models for teacher-student style optimization, you can also use same model for both train and test) WILL NOT go to production.
Only the agent definition, signature of the prompt, compiled miprov2_agent.json WILL go to the production.
DSPy itself (dspy-ai in requirements.txt) also goes to production, because it is the engine that reads the JSON and assembles the prompt at runtime.
The next question is where do you write the Signatures, where do you use etc.
DSPy is something you work with at the time of development and most part of the code does not go to production at all.
Development
runs once · 15–60 min
Write signatures
Define inputs, outputs, and docstring for each LLM step
↓
Collect labeled examples
30–50 real input/output pairs covering edge cases
↓
Write metric function
Python function that scores prediction vs ground truth
↓
Run optimizer
~150 LLM calls · finds best instruction + examples
↓
Save agent.json
Best prompt frozen to disk · training data never runs again
↓
agent
.json
.json
best prompt
frozen
frozen
↓
deploy
Production
every request · 1–3 sec
Customer message arrives
User sends a message to your application
↓
Load agent.json
DSPy reads saved prompt · no optimizer · no training data
↓
DSPy builds the prompt
Saved instruction + examples + customer message assembled
↓
One LLM call
Prompt sent to LLM · response received
↓
Return result
intent, confidence, response returned to your app
The optimizer never runs in production. DSPy is installed but only does prompt assembly and one LLM call per request.
Development — happens once
Production — happens every request
From the above infographic, whatever you did till now are all in development. You still cannot see the prompt which goes to LLM.
DSPy takes in the miprov2_agent.json and runs it at runtime to build the prompt. The prompt is built on runtime and send to LLM.
No optimization or training will be done in production.
The complete notebook
Everything we’ve covered is available as a runnable Jupyter notebook — 10 sections you can step through live. It runs top-to-bottom: baseline eval → optimization → comparison → live inference with your own messages.
Jupyter Notebook: customer_care_dspy.ipynb
Running it locally
=> PowerShell (Windows)
# 1. Clone and enter the repo
git clone https://github.com/aasha01/DSPy.git
cd customer-care-dspy
# 2. Create .venv and install dependencies (run with .\)
.\setup.ps1
# 3. Pull Ollama models
ollama pull qwen2.5:14b
ollama pull qwen2.5:32b
# 4. Open in VS Code — kernel auto-selected
code .