Imagine it is 2016.
I want to build a machine translation model that converts English into Tamil.
I give it this sentence: The dog chased the cat because it was fast.
Seems simple.
But hidden inside this sentence is a difficult problem:
Who was fast?
Was it the dog?
Or the cat?
That single ambiguity exposes one of the biggest limitations in early neural translation systems.
Let’s walk through why.
The Early Seq2Seq Idea:
The classic sequence-to-sequence models were built with models like Long Short-Term Memory (LSTM).
They had three major pieces:
- Encoder
Think of this like someone reading a sentence and understanding it.
- Context Vector
This is like a summary of what was read — a single “idea” or “memory”.
- Decoder
This is like someone taking that idea and rephrasing it in another language (or generating a response).
To understand more about Vectors please visit Understanding vectors and why its representation is used in Embedding
What happens in Seq to Seq:
Step #1: The encoder takes the input word by word and processes it:
“The” → h1
“dog” → h2
“chased”→ h3
“the” → h4
“cat” → h5
“because”→ h6
“it” → h7
“was” → h8
“fast” → h9
Step #2: Old Seq2Seq Compresses Everything into a dense fixed size vector.
The context vector should contain all the information about the sentence such as subject, object, action, relationships between them, even the pronoun reference of “it,” etc.
The Bottleneck Problem:
Now the model should know, who was fast, dog or cat? What should the word “it” refer to?
This is where it gets interesting.
If “it” refers to “dog” then the translation would be something like,
நாய் வேகமாக இருந்ததால் பூனையை துரத்தியது
(As Dog was fast)
If the same refers to “cat”, then,
பூனை வேகமாக இருந்ததால்…
(As Cat was fast)
Wrong referent changes the sentence meaning – Wrong translation.
The issue is not vocabulary.
It is relationship tracking.
Early Seq2Seq often lost those relationships because everything was compressed into one vector.
This became known as the encoder bottleneck.
Early Attention mechanism – By Bahdanau, Cho, and Bengio in 2014–2015:
To solve this weakness, the first attention mechanism introduced by Bahdanau, Cho, and Bengio in 2014–2015 is used within the decoder at each generation step.
RNNs with attention enabled better translation of long sentences and improved performance in tasks like speech recognition and text generation.
What Attention does in RNN?
RNN + Attention Architecture: Attention is applied INSIDE the decoder at every step:
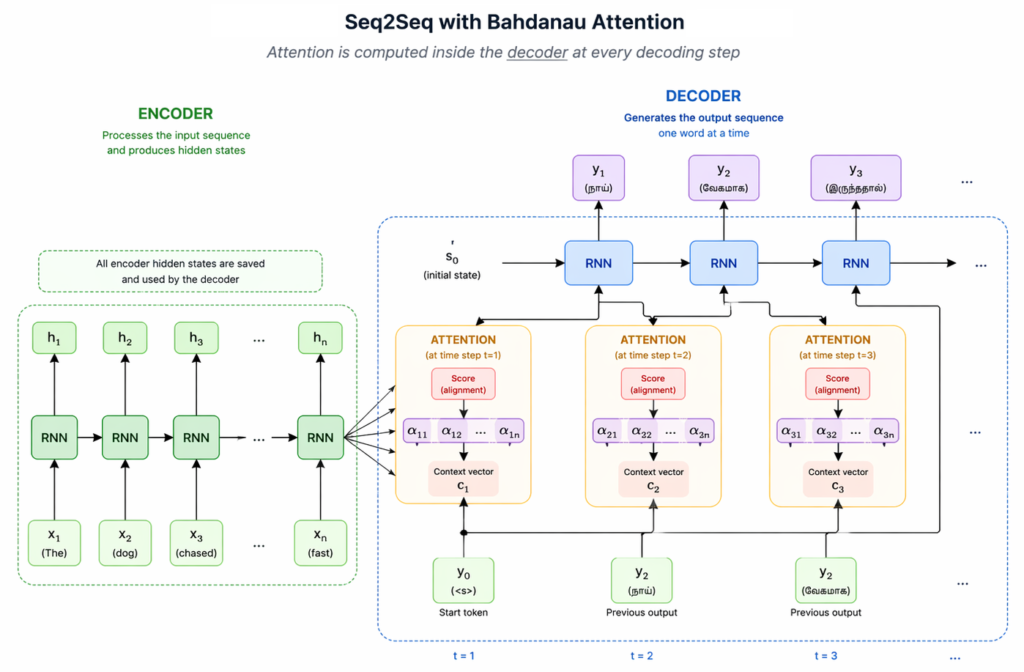
After the encoder has processed the input, decoder starts with first word
At each decoding step:
Before generating each word of output, the model looks back and determines which words deserve more attention.
When decoder reaches translating “it was fast…”, it can look back
dog ← high attention
cat ← lower attention
Instead of relying only on a fixed context vector, the decoder can dynamically revisit relevant encoder states. This attention mechanism is called as Cross-Attention.
In cross-attention, the decoder asks, “Which input words matter right now?”
That question acts as a Query.
Encoder words provide Keys and Values, and the model pulls the most relevant information into a context vector.
Even After Attention… What Was Still Wrong?
Problem #1: Reading One Word at a Time Was Slow
You cannot speed it up much because the next step depends on the previous one.
Analogy:
It’s like cooking one dosa fully before starting the next one.
Transformers later allowed cooking many dosas at once 😄
Problem #2: Memory Could Still Fade
Even with attention helping sometimes, the model still carried memory step by step because it still processes one word at a time, and long complicated relationships could get blurry.
Analogy:
Like trying to remember the beginning of a very long phone number while someone keeps adding more digits.
Problem 3 — Attention Was Only Used as a Helper
Input words were encoded through recurrence, but they did not directly attend to one another. Attention existed only in the decoder.
When researchers realized Problem #3, another idea came up “Why only add attention in decoder?!”
Why not let all words talk to each other from the start?
Why wait till the process reaches Decoder + Attention?
This was a turning point — this is where the Transformer architecture emerged.
Transformers used attention as entire model than using only in the decoder.
The research paper “Attention Is All You Need” was published on 2017 which drastically changed the Generative AI world.
From the paper:
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
Cross-Attention:
In this encoder-decoder model, when the decoder is generating the next word, it may need information from the input sentence.
It does this through cross-attention:
- The decoder creates a Query (what information it needs right now)
- The encoder hidden states act as Keys (what each input word offers)
- Those same encoder states provide Values (the information that can be pulled)
The query is compared against all keys, and the model gives higher attention to the most relevant words.
Those weighted values are combined into a context vector, which helps generate the next output word.
This is called cross-attention because the decoder is attending across to the encoder.
Key Takeaways:
- Early Seq2Seq models had a memory problem.
They tried to squeeze an entire sentence into one summary, which could lose important meaning. - Attention helped models focus.
Instead of relying only on one summary, the model could look back at important words when needed. - But RNNs still had limits.
They were slow, handled long relationships poorly, and used attention only as extra help. - Transformers changed that.
They made attention the main way the model works, instead of just a supporting feature. - That idea led to modern AI models like GPT.
The path to GPT began with a simple problem in translation: models needed not just to remember words, but to understand relationships between them.
Thanks to:
- Conference paper published at ICLR 2015: NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
- Attention Is All You Need
- Self-Attention vs Cross-Attention: From Fundamentals to Applications