Ever wondered what the T in GPT stands for?
Yes — Transformer (Generative Pre-trained Transformer).
Let’s start with Why Transformers?
Before Transformers, we had Recurrent Neural Networks and Long Short-Term Memorys for Seq2Seq models.
These models had a problem: they lacked parallelism in input processing, which made training slow.
Another limitation was that cross-attention was introduced only as a mechanism alongside recurrent networks, mainly helping the decoder focus on relevant parts of the input. But the encoder still processed inputs one by one, making long-range dependencies harder to capture.
To overcome this, a few fundamental questions emerged:
- Why use attention only in decoders?
- Do we really need recurrence at all?
- What if attention itself became the core architecture?
That’s how the attention mechanism took over the Seq2Seq architecture — and this led to Transformers.
Self-Attention in Transformers — From “Attention Is All You Need”:
Per the name, this architecture has excluded the RNN and only has Attention in both Encoders and Decoders.
Before diving into the Architecture, lets see what is Self-Attention in this architecture and how it is done.
Interesting Fact: In cross-attention, the decoder asks, “Which input words matter right now?”
That question acts as a Query.
Encoder words provide Keys and Values, and the model pulls the most relevant information into a context vector.
What if the encoder itself adjusts token representations before sending them to the decoder? It has to attend on itself, and do the context pull, which is called self-attention. Lets learn more about this.
Scaled Dot-Product Self-Attention:
The paper Attention Is All You Need describes attention as a mapping from a query and a set of key-value pairs to an output, where Queries (Q), Keys (K), and Values (V) are all vectors.
The output is a weighted sum of the values.
They call this particular attention mechanism as “Scaled Dot-Product Attention”.
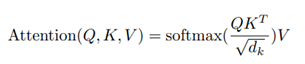
Here is what happens:
- Compare each word with every other word: Q X K^T
This gives similarity scores between a word’s query and all other words’ keys. - Scale the scores: For larger dimensions, dot products can become large in magnitude, which may push Softmax into regions with very small gradients (vanishing gradient issue).
To stabilize this, scale by 1/ √dk.
- Convert to attention weights and combine information: Use the resulted weights to combine information – Multiply by Values, which is the final attention.
Queries, Keys and Values Intuition
What are Queries, Keys and Values?
Now, you might think, what are these Queries, Keys & Values. Let’s look at the core detail of the attention mechanism.
When processing input vectors in the encoder, the model needs to understand how each word relates to every other word.
For example, Take this sentence:
“The cat sat on the mat because it was tired.”
When we process the vector for the word “it”, we need to determine whether “it” refers to cat, mat, or something else.
Without context, the meaning may be ambiguous.
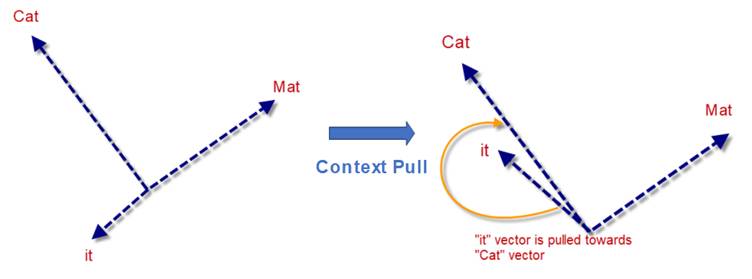
In vector space, let’s say the word “it” should point in a direction more similar to cat than to sat or mat. That is when the model understands that “it” refers to cat.
If the word “it” initially aligns more closely with mat or sat, training updates the model to pull “it” toward cat. We can view this intuitively as a context pull.
(For simplicity in this toy numerical example, we use “cat” and “mat” to illustrate how training can correct an initially imperfect attention pattern.)
In order to do this context-pull, each word is processed with 3 perspectives,
“What this current word is looking for?” -> Query (Q)
“What does each word offer or represents to this current word?” -> Key (K)
“What each word actually means to the current word? (actual information)” -> Values (V)
| Query asks a question, Keys decide relevance, Values provide the answer. |
For our example, we find the attention for each word by comparing the current word with all other words.
Especially, the word “it” has to be understood properly otherwise “it” might get confused with “mat” than “cat”.
Query (Q) → representation of “it” (what it’s trying to understand)
Keys (K) → representations of all words (“cat”, “mat”, etc.)
Values (V) → actual meanings/info of those words
The model:
- Compares “it” (Q) with all keys (K)
- Finds “cat” is most relevant
- Uses the value (V) of “cat” to understand “it”
Let’s walk through the example for the computation of the attention vector of “it”.
Step 1: Word embeddings (starting point)
Lets pretend that the word embeddings are in 3D, which are the input matrix X.
| Word | Embedding |
| cat | [1, 0, 1] |
| sat | [0, 1, 1] |
| mat | [1, 1, 0] |
| it | [0, 1, 0] |
Step 2: Create Q, K, V
Take the random values and then we get the learned matrices:
Wq, Wk, Wv (each of shape 3×2)
Initialized randomly, then optimized during training.
| Why?Because we projected from embedding dimension 3 into attention dimension:dk=2d_k = 2dk=2 |
Step 3: Compute Q, K, V for key words
For “it”, input is multiplied with Q
Qit = X1 X Wq = [0,1,0] X Wq = [0, 1]
Keys
cat -> [1,0,1] × Wk = [2,1]
sat -> [0,1,1] × Wk = [1,1]
mat -> [1,1,0] × Wk = [1,2]
Values
- cat → [2,1]
- sat → [1,3]
- mat → [1,2]
Step 4: Compute attention scores (Q · K)
Now compare “it” with all words
Dot products
- it · cat → [0,1] ⋅ [2,1] =1
- it · sat → [0,1] ⋅ [1,1] =1
- it · mat → [0,1] ⋅ [1,2] =2
scores are [1,1,2]
Step 5: Scale
Now dk=2→2≈1.41
Scaled value = [0.71, 0.71, 1.41]
Step 6: Softmax (convert to weights)
Approx:
- e^ {0.71} ≈ 2.03
- e^ {1.41} ≈ 4.10
[2.03,2.03,4.10] →normalized→ [0.25,0.25,0.5]
Attention weights for “it”:
| Word | Weight |
| cat | 0.25 |
| sat | 0.25 |
| mat | 0.5 |
Step 7: Weighted sum of Values (Context Pull)
Now multiply these normalized scores with the Value vector.
Output(it)=0.25× [2,1] +0.25× [1,3] +0.5× [1,2]
Calculate:
- 0.25 × cat → [0.5, 0.25]
- 0.25 × sat → [0.25, 0.75]
- 0.5 × mat → [0.5, 1]
Sum: [1.25,2]
At this stage, the attention weights show that “it” attends more to “mat” than “cat.”
This might seem incorrect—but this is actually expected.
The model is still untrained, and the matrices Wq, Wk, Wv are randomly initialized. So the attention scores do not yet reflect true language understanding.
What we are seeing here is not a failure, but a starting point.
During training:
- Backpropagation updates these matrices
- The model learns patterns of word relationships
- The attention gradually shifts toward the correct context
Over time, the representation of “it” is pulled closer to “cat”, resulting in a context-aware embedding where the model correctly understands the reference.
This is the key idea: attention is not predefined—it is learned.
What we have seen so far is a single attention mechanism.
But language is rich, and a single perspective is often not enough to capture all relationships between words.
Transformers address this using Multi-Head Attention, where multiple attention mechanisms run in parallel, each learning a different way words relate to each other.
You can think of it like reading reviews where you don’t rely on just one opinion, but consider multiple perspectives before forming a conclusion.
Similarly, each attention head focuses on different aspects such as meaning, syntax, or long-range dependencies, and together they provide a richer understanding of the sentence.
Now we are ready to dive into the complete architecture of Transformers, where multi-head attention plays a crucial role.
We will explore that in the next article!
Key Takeaways
- Transformers replace recurrence with attention, enabling better parallelism and long-range understanding
- Self-attention allows each word to learn from every other word in the sentence
- Queries, Keys, and Values work together to build context-aware representations
- Attention is learned through training, not predefined
- Multi-head attention helps the model capture multiple types of relationships simultaneously
Reference Links:
- Attention Is All You Need
- https://medium.com/@xiaxiami/self-attention-vs-cross-attention-from-fundamentals-to-applications-4b065285f3f8