
In the previous article about SpaCy Vs NLTK SpaCy Vs NLTK – Basic NLP Operations code and result comparison, we have compared the basic concepts. In this article, we will explore about Stemming and Lemmatization in both the libraries SpaCy & NLTK.
Stemming is a process of converting the word to its base form.
For example, converting the word “walking” to “walk”
It just chops off the part of word by assuming that the result is the expected word. As this is done without any grammer based, sometimes, Stemming may go wrong.
SpaCy:
SpaCy does not provide a built-in function for Stemming as Stemming is not accurate and SpaCy is mainly created for Production level use. Inaccurate process is not obviously not useful for Production.
However it provides Lemmatization.
Lemmatization does the same job but more accurately with the help of language specific dictionary and returns the exact root word.
Steps to do Lemmatisation:
- Import SpaCy
- Load the trained Language Pipeline. This will contain all the components and data to process text.
- Passing the text to this trained pipeline will provides an object with all information about the text. Example: Tokens, Lemmas, Is_Stop word?, Parts Of Speech information etc.
- Iterate over the words and extract the Lemma values.
Example #1:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp('Walking is one of the main gaits of terrestrial locomotion among legged animals')
for token in doc:
print(token.text + "-->" + token.lemma_)
Walking-->walk is-->be one-->one of-->of the-->the main-->main gaits-->gait of-->of terrestrial-->terrestrial locomotion-->locomotion among-->among legged-->legged animals-->animal
Example #2:
doc = nlp("The brown foxes are quick and they are jumping over the sleeping lazy dogs")
for token in doc:
print(token.text + "-->" + token.lemma_)
The-->the brown-->brown foxes-->fox are-->be quick-->quick and-->and they-->they are-->be jumping-->jump over-->over the-->the sleeping-->sleep lazy-->lazy dogs-->dog
NLTK:
There are also other libraries like SpaCy which provides Stemming functions.
In NLTK, built-in functions for Stemming is available even though it is slightly inaccurate.
Example #1:
from nltk.stem import PorterStemmer
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
ps = PorterStemmer()
sentence1 = "Walking is one of the main gaits of terrestrial locomotion among legged animals"
sentence2 = "The brown foxes are quick and they are jumping over the sleeping lazy dogs"
words = word_tokenize(sentence1)
print("Stemming:")
print("=========")
for w in words:
print(w, " : ", ps.stem(w))
print("\nLemmatization:")
print("==============")
lemmatizer = WordNetLemmatizer()
for w in words:
print(w, " : ", lemmatizer.lemmatize(w))
Stemming: ========= Walking : walk is : is one : one of : of the : the main : main gaits : gait of : of terrestrial : terrestri locomotion : locomot among : among legged : leg animals : anim Lemmatization: ============== Walking : Walking is : is one : one of : of the : the main : main gaits : gait of : of terrestrial : terrestrial locomotion : locomotion among : among legged : legged animals : animal
Example #2:
words = word_tokenize(sentence2)
for w in words:
print(w, " : ", lemmatizer.lemmatize(w))
The : The brown : brown foxes : fox are : are quick : quick and : and they : they are : are jumping : jumping over : over the : the sleeping : sleeping lazy : lazy dogs : dog
Now we have tried Lemmatization in both SpaCy & NLTK.
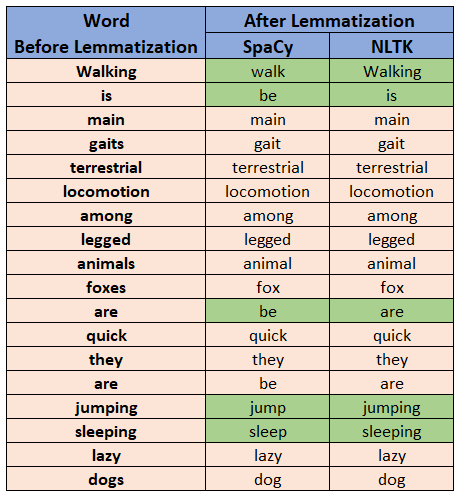
Comparison of results from SpaCy & NLTK:
In the below result, you can see that the results marked in Green are different in SpaCy & NLTK.
Some words like walking, jumping, sleeping are more accurate in SpaCy.
However is, are are converted to “be” as a root form in SpaCy.
As SpaCy is built for production use it’s pipelines are more trained and provides more accuracy than NLTK.
To learn more about SpaCy and NLTK, visit the article SpaCy Vs NLTK – Basic NLP Operations code and result comparison that explains the comparison between SpaCy and NLTK with the sample code.